
Elated to share that the paper that I co-authored at BrainChip, aTENNuate, has been accepted at Interspeech 2025
If you are at Rotterdam from August 17-21, 2025, and want to have a chat on speech technologies, feel free to hit me up!
May 19, 2025
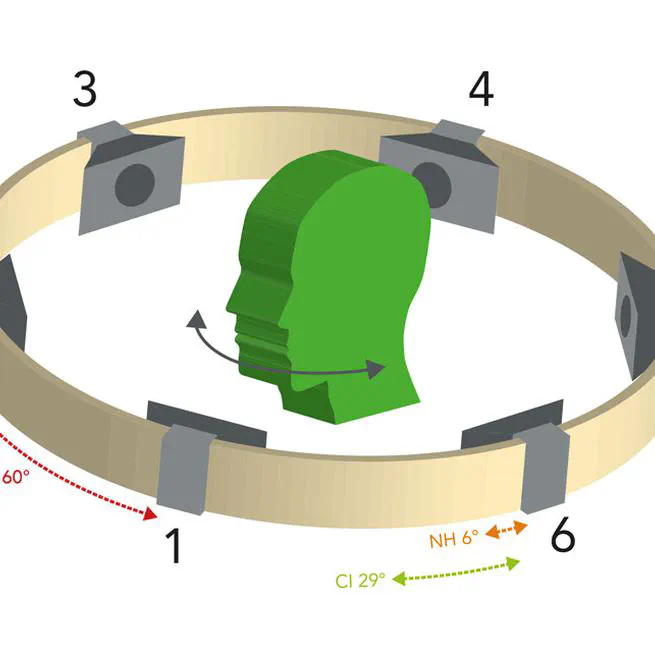
aTENNuate based masked channel signal reconstruction in simulated environments
Developed an SSM architecture to predict masked channel audio signal at a desired location in a simulated room given source and microphone configuration. This model learns the spatial audio representation via self-supervised learning technique
Feb 2, 2025

🎧 aTENNuate submitted to Interspeech 2025
Our work on audio denoising using SSMs at BrainChip was recently submitted to Interspeech 2025.
Jan 25, 2025