aTENNuate based masked channel signal reconstruction in simulated environments
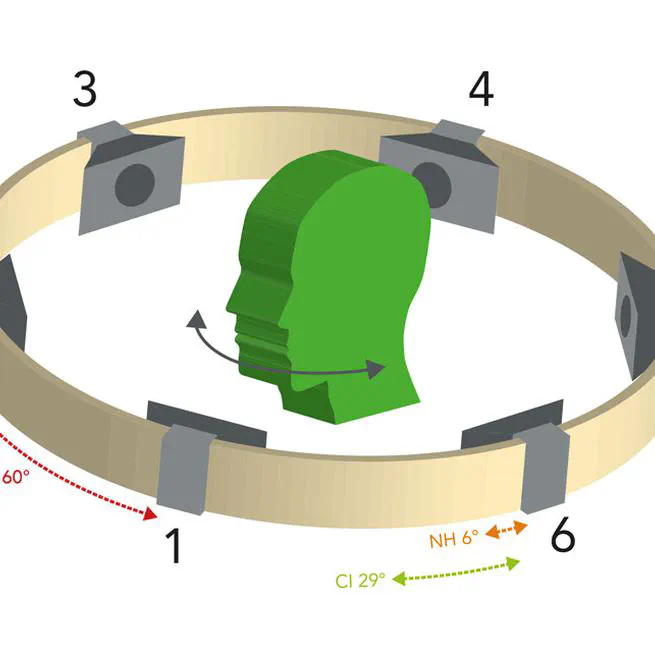
Developed an SSM architecture to predict masked channel audio signal at a desired location in a simulated room given source and microphone configuration. This model learns the spatial audio representation via self-supervised learning technique
Feb 2, 2025

aTENNuate
Developed a Deep SSM for real-time audio denoising for edge AI applications.
Sep 5, 2024

Odessa a speaker dependent ASR using HMM
This is a basic HMM-based ASR that uses MFCC and delta features to identify six phrases: “Odessa” (a keyword phrase), “Play music,” “Start music,” “Turn off the lights,” “Turn on the lights,” and “What time is it.”
May 31, 2024